
pandas를 위해 필요한 것
pandas는 기본적으로 하나의 모듈이 아니라, pandas를 사용하기 위해 여러 모듈들을 같이 설치하는 구조로 되어있다. 따라서 pip로 설치해보면 pandas만 깔리는 것이 아니라 여러 모듈들도 같이 깔린다. 그 중에 제일 중요한게 numpy인데, 실제로 pandas 모듈만 따로 레이어에 업로드해보면, 작동하지 않는다.
aws-lambda는 amazon linux에서 돌아가는데, amazon linux는 PyPi나 conda-forge에서 설치하는 보통 numpy를 사용할 수 없다고 한다.
방법
사실 방법은 두 가지 정도가 존재하는데, 첫 번째 방법은 pandas와 그에 필요한 pytz 딱 두 개를 다운 받아서 레이어에 업로드하고 부차적으로 필요한 numpy나 scipy를 AWS 계층을 이용해 추가하는 방법이고 두 번째는 사용자 지정 ARN을 이용하여 직접 모듈 파일을 만들지 않고 이용하는 것이다.
나는 이번 챗봇을 만들면서 첫 번째 방법을 사용했는데, 다음 사이트를 참고했다. 첫 번째 방법을 원하시는 분들은 보시면 될 것 같다.
https://medium.com/swlh/how-to-add-python-pandas-layer-to-aws-lambda-bab5ea7ced4f
How to add Python Pandas layer to AWS Lambda
There is no question about the brilliance of the Pandas library. One of the most used libraries in data science, Pandas is a household…
medium.com
여기서 소개할 방법은 두 번째 방법으로 사용자 지정 ARN을 이용한 방법이다. 사실 제일 간편하고 쉽다.
https://github.com/keithrozario/Klayers
GitHub - keithrozario/Klayers: Python Packages as AWS Lambda Layers
Python Packages as AWS Lambda Layers. Contribute to keithrozario/Klayers development by creating an account on GitHub.
github.com
이곳에 들어가면, 사용할 수 있는 ARN들이 있다. 2022.05.22 기준으로 존재하는 것은 python 3.8과 3.9 버전의 ARN인데, 나는 3.8버전을 택했다.

List of ARN's에서 python 3.8을 택하면 다음과 같은 리스트가 나타난다.

자신이 함수를 업로드할 리전을 선택해서 ARN리스트를 보면된다. 나는 서울을 택했기 때문에 ap-northeast2의 html을 누르면

다음과 같은 리스트들이 나타난다. 이중에 pandas를 찾아 ARN을 복사한다.

자신이 실행하고자 하는 함수에 들어간 후 맨 밑으로 스크롤을 내리면 계층 메뉴가 존재한다.
여기서 Add a layer를 누르면 다음과 같은 화면이 보인다.
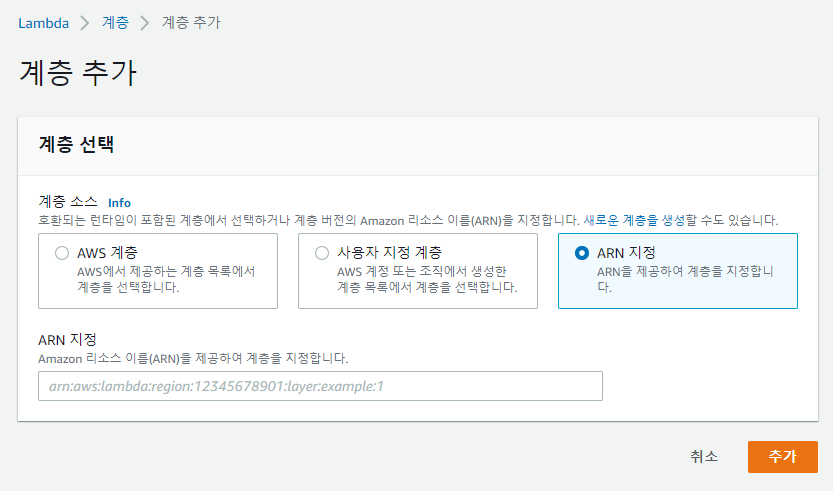
여기서 ARN 지정을 선택하고 복사한 주소를 붙여넣기하여 추가해주면 된다.
그러면 따로 numpy랑 scipy를 추가하지 않아도 pandas가 잘 작동하는 것을 볼 수 있다. 추가로 read_excel같은 메서드를 사용하려면 openpyxl 모듈이 필요하다. 이것도 ARN 리스트에 존재하므로 잘 찾아서 쓰면 될 것 같다.
'Backend > AWS' 카테고리의 다른 글
| aws lambda에서 파이썬 selenium 동작하게 하기 (0) | 2022.05.22 |
|---|