
이번에 챗봇 프로젝트를 진행하면서 웹 페이지에서 생성되는 파일 이름을 읽어올 필요가 있었다.
처음에는 requests를 이용하려 했으나, 그것이 동적으로 생성되는 데이터임으로 깨닫고.. selenium으로 변경했다. 그리고 이것을 실행할 환경인 aws lambda에서 돌아가게할 필요가 있었다.
selenium 모듈 파일부터 구해야..
aws-lambda에서는 라이브러리를 따로 레이어 계층이란 곳에 추가시켜줘야 사용할 수 있다. 이 때 레이어는 파이썬 모듈 파일들을 zip로 압축한 파일들을 말하며, 이런 레이어들을 각 함수에서 추가시켜주면 된다.
우선 selenium을 aws-lambda에서 동작시키는데에는 3가지가 필요하다. chromedriver, headless-chromium, selenium이다.
그냥 일반 환경에서 실행시킬 때는 chromedriver와 크롬이면 충분하나 aws lambda에는 크롬이 없으므로 다른 선택지가 필요하다. 따라서 여기서 headless-chromium을 사용한다.
여러 곳에서 방법을 찾다가, 깃허브에 이미 작동되는 모듈을 모아놓은 사람이 있어서 그것을 그대로 가져다가 사용했다.
https://github.com/ManivannanMurugavel/selenium-python-aws-lambda
GitHub - ManivannanMurugavel/selenium-python-aws-lambda
Contribute to ManivannanMurugavel/selenium-python-aws-lambda development by creating an account on GitHub.
github.com
해당 레포지토리를 다운 받은 후 dist-info 디렉터리는 필요없으므로 삭제해준다. 물론 버전 정보를 위해 남겨놔도 무방하다. README도 삭제하고, zip파일도 삭제한다. 새로 압축할 것이기 때문이다. .py파일들도 지우거나 남겨도 상관없다. 다만 용량을 위해 삭제하는 것을 더 추천한다. 나는 여기서 삭제하는 것을 택했다. 그러면 이제 모듈 폴더들만 남아 있을 것이다.
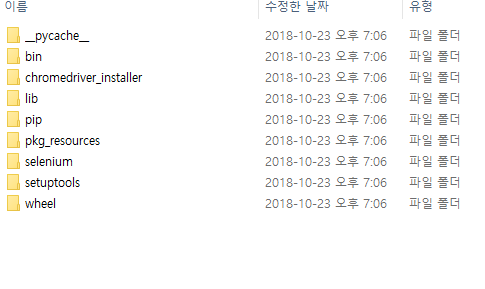
여기서부터 중요한데, 새로 'python'이라는 이름을 가진 폴더를 만들어 거기에 모든 폴더를 다 넣는다.
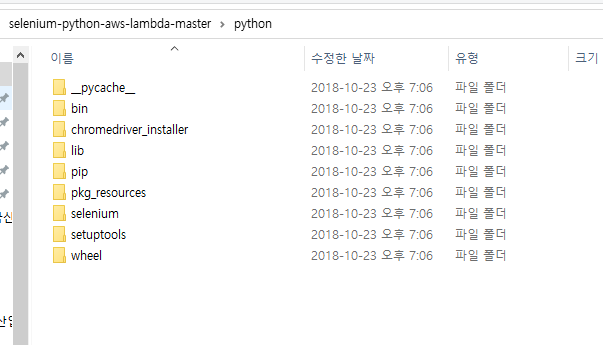
그러면 이런 구조가 만들어질 것이다. 이렇게 해야 lambda에서 모듈을 인식할 수 있다.
후에 이를 통째로 압축하면 된다.
aws-lambda 레이어에 업로드
이제 aws-lambda로 들어간다. 밑의 사진들은 2022.05.22 기준이다. 메뉴를 보면 계층이란 곳이 존재한다.

이 곳에 들어가서 계층 생성 버튼을 누른다.

이름과 설명은 쓰고싶은 대로 쓰면 되고, 업로드 버튼을 눌러 아까 압축한 zip를 업로드한다.
호환 런타임은, 여러 번 실험해본 결과 python 3.6을 초과하는 버전에선 작동이 안된다. chromedriver의 오류로 나오는걸로 봐서는 호환성에 오류가 있나보다. 따라서 python 3.6으로 맞춰준다. 물론 다른 환경에서 테스트 해보고 싶다면 python 3.6~9까지 원하는 버전으로 호환 런타임 설정해주면 된다. 설정해준 런타임 외에 곳에서는 레이어를 추가하지 못하기 때문이다.
이후 생성 버튼을 눌러 레이어를 생성하면 된다.
생성 완료했다면, 이제 함수에 들어간다. 물론 함수의 런타임 환경도 python 3.6이어야 한다.

여기서 맨 밑에 내려보면 계층이 존재하는데 Add a layer 버튼을 눌러준다.

그 후에 계층 선택이 나오는데, 사용자 지정 계층에서 자신이 업로드한 레이어를 설정하고 버전은 처음 업로드 했으니 혼자 존재하는 1로 설정해주면 된다.

나는 이미 올려놓고 수정해서 버전이 2다. 그리고 추가를 눌러준다. 그럼 이제 레이어가 추가될 것이다.

selenium을 위한 코드
근데 레이어만 업로드 했다고, 동작하지 않는다. aws-lambda는 일반적인 환경이랑 다르므로 여러 설정들을 전에 해줘야하는데, 아까 올린 레포지토리의 lambda_handler.py 파일에 그것이 정리되어있다.
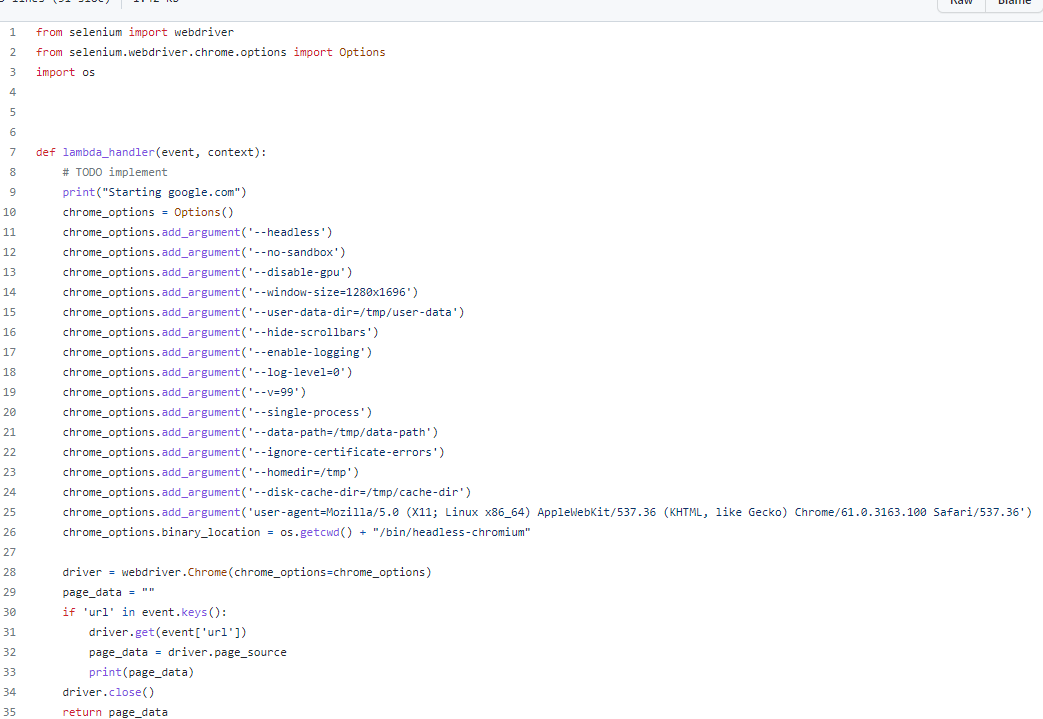
바로 이 내용인데, 28번줄 뒤의 내용은 실행하는 코드이고 우리는 환경설정 코드만 필요하다. 그러므로 10 ~ 28줄만 복붙한다. 여기서 수정해줘야할 사항이 조금 있다. 우리는 아까 python폴더 안에 모듈들을 넣고 압축시켰다. 그 속에는 bin 폴더도 있었는데 바로 여기에 chromedriver와 headless-chrome이 저장되어 있다. 따라서 경로를 조금 수정시켜줘야 할 필요가 있다.
# chrome_options.binary_location = os.getcwd() + "/bin/headless-chromium"
chrome_options.binary_location = "/opt/python/bin/headless-chromium"
# driver = webdriver.Chrome(chrome_options=chrome_options)
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path='/opt/python/bin/chromedriver')위처럼 변경해주면 된다.
그 후에 일반적인 환경에서 selenium을 동작시키는 것처럼 코드를 짜면 실행이 될 것이다.
예제가 필요하다면 내가 짠 코드를 보면 좋을 것이다.
https://github.com/somewheregreeny/menuplanner-chatbot
GitHub - somewheregreeny/menuplanner-chatbot: 한국공학대학교 TIP 지하 식당과 E동 식당의 메뉴를 알려주는
한국공학대학교 TIP 지하 식당과 E동 식당의 메뉴를 알려주는 챗봇. Contribute to somewheregreeny/menuplanner-chatbot development by creating an account on GitHub.
github.com
이틀 동안 삽질해서 작동시켰는데.. 쓰고 보니 몇 줄 안된다. aws lambda에서 selenium 동작시키기에 고통 받는 사람을 위해 바친다 ㅠㅠ
'Backend > AWS' 카테고리의 다른 글
| aws lambda에서 pandas 사용하기 (0) | 2022.05.22 |
|---|